StructDiffusion
Building structures requires models that can reason about different constraints over where objects should be at once (e.g., object geometry, language-driven task semantics, physics) and generate solutions that respect all these constraints.
StructDiffusion consists of: (1) an object-centric, language-conditioned diffusion model, which learns how to construct different types of multi-object structures from observations of novel objects and language instructions, and (2) a learned discriminator, which drastically improves performance by rejecting samples violating physical constraints.
Generating Diverse Goals with Object-Centric Diffusion
We use unknown object instance segmentation to break our scene up into objects, as per prior work (e.g., [1], [2], [3]). Then, we use a multi-modal transformer to combine both word tokens and object encodings from Point Cloud Transformer in order to make 6-DoF goal pose predictions.
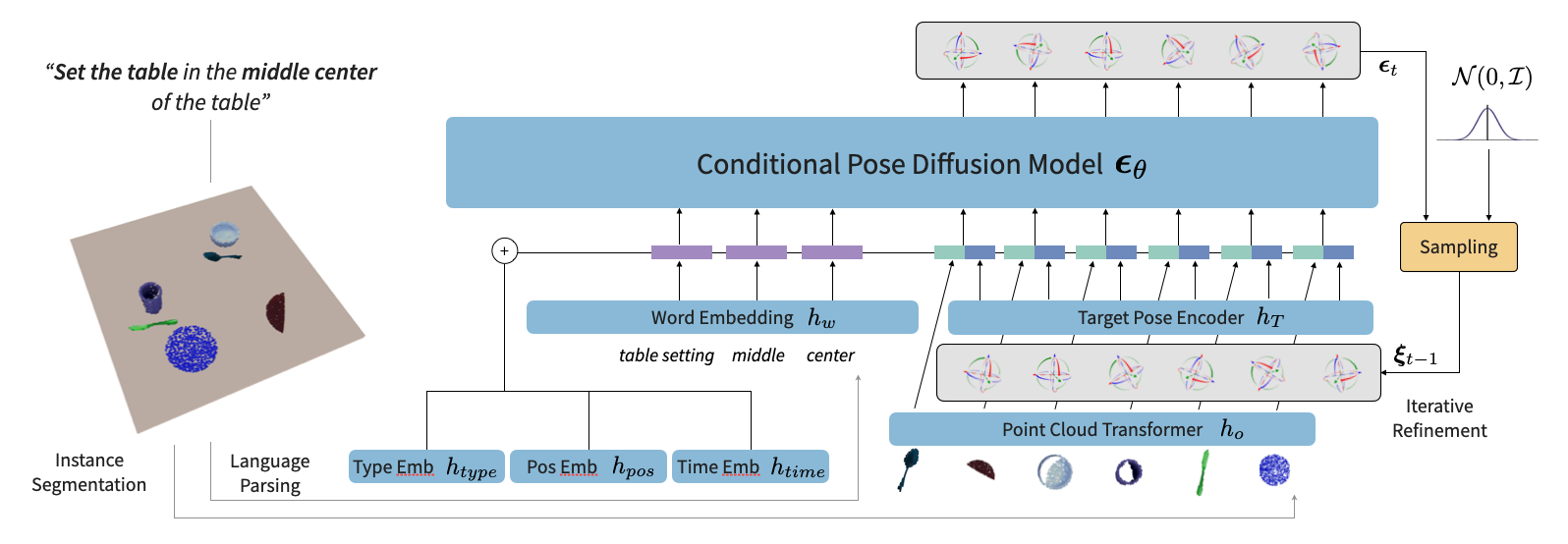
Our diffusion model is integrated with a transformer model that maintains an individual attention stream for each object. This object-centric approach allows us to focus on learning the interactions between objects based on their geometric features as well as the grounding of abstract concepts on spatio-semantic relations between objects (e.g., large, circle, top).
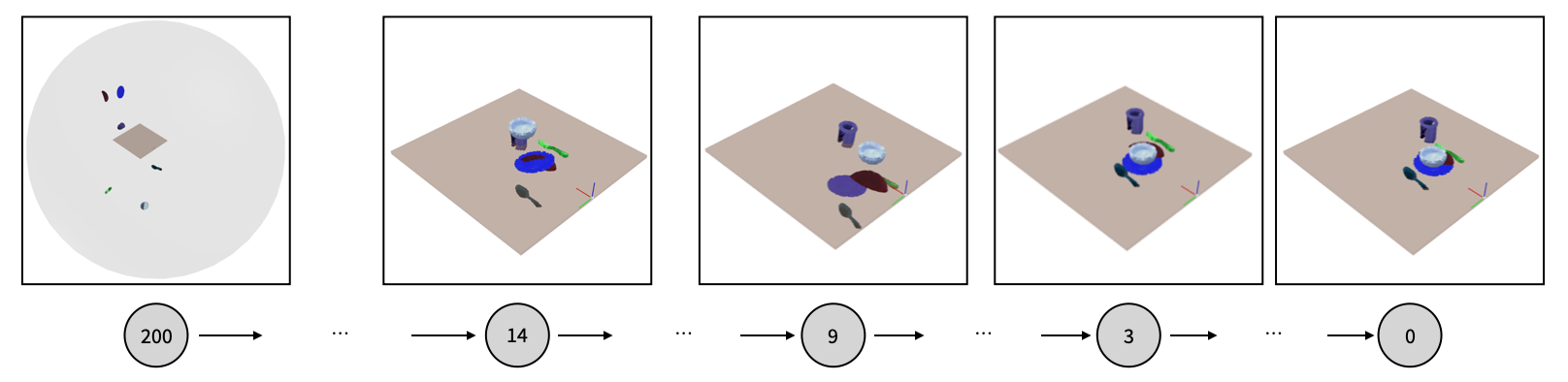
We start from the last step of the reverse diffusion process and jointly predict goal poses for all objects in the scene. This allows our model to reason about object-object interactions in a generalizable way, which outperforms simply predicting goal poses from multi-modal inputs.